






はじめに
荷主や物流事業者が運営管理する物流センターにおいて、物流データを取扱う際、基本的な統計の知識の重要性が、見直されています。
本稿では、初めに、物流データに関する基本的な知識について、物流現場において実際に利用されている入荷予定データのイメージを用いて紹介します。
次に、基本統計量の用語の説明や、基本統計量の使い方など、基本統計量の基本知識を整理します。
物流データに関する基本的な知識の整理
物流データの取り扱いが必要な理由
物流データの取り扱いが必要な理由は、物流現場の運営管理において、物流データを用いた定量的な把握が必要とされているためです。定性的または勘と経験に依存して物流現場を管理した場合には、物流コストの削減、物流品質、効率性や生産性の向上に関して、期待する効果や成果は得られない場合が多くなります。
物流データの活用方法
物流データを活用する主な3つの活用方法を以下に整理します。
1.現状把握に活用する。
現状の入出荷の作業実績、在庫状況、配送実績等を数値で把握します。
2.予実管理に活用する。
物流現場における作業予定と作業実績を比較して、その差異を明らかにする。
3.レポート作成時に活用する。
レポートで述べる主張を客観的データに基づいて補完する。物流業界では、荷主、顧客、社内向けに、計画立案、提案、報告等を行う際の各種資料の作成がしばしば発生します。また、荷主や物流会社においては、レポート作成は、物流品質、物流コスト、配送納期等の管理業務において、非常に重要な業務と位置付けられていることが多いです。
このように、物流を管理する荷主や物流会社においては、物流データを取扱うことが、必須と言えます。
物流データが発生する領域とデータ量
物流データには、様々な領域のデータが存在します。例えば、入荷データ、在庫データ、出荷データ、配送データ、作業実績データなどです。また、一般的に、荷主の物流の動きに伴い、継続的に、日々、物流データが発生します。
よって、上記の領域および期間を考慮すれば、膨大な物流データが日々、発生しています。たとえデータ量が多くても、できる限り正確な情報から分析するために必要なデータ量を取得し、分析する必要があります。一般的には1年間分のデータを分析することが望ましいのですが、データの取得・分析に多くの時間と費用が発生する場合は、繁忙期・閑散期・平常期の3期間のデータを用いる場合もあります。
物流データのデータ構成事例
次に、物流データのデータ構成について紹介します。表1に、入荷予定データを示します。
表1 入荷予定データのイメージ

出所:各種資料より日通総研作成
表1は、物流センターにおいて、ベンダーから入手する日次の入荷予定データのイメージです。表1の入荷予定データのデータ項目は、左から入荷日、ベンダーコード、ベンダー名、商品カテゴリコード、商品カテゴリ名、商品コード、商品名、入荷数量(個)から構成されます。
表1のベンダーコードとベンダー名、商品カテゴリコードと商品カテゴリ名、商品コードと商品名のように、“コード”と“名”が対になっているデータ構成の場合、集計結果が昇順で並び替えられるため、結果の整理が容易となります。
また、表1のように、商品カテゴリ区分が含まれれば、カテゴリ別の物流の特徴などが把握しやすくなります。例えば、カテゴリ別に頻度や件数や数量などの特徴を把握することができます。
なお、表1は、ASN(Advanced Shipping Notice)と呼ばれることがあり、入荷予定データや事前入荷情報と訳されることが多いです。
入荷予定データがあると便利なこと
物流現場では、表1のような入荷予定データが入手できると、効率的な運用に活用しやすくなります。
例えば、自社の生産工場から全量が入荷する物流センターであれば、入荷予定データの入手が容易であり、入荷予定データを活用した効率的な入荷検品の仕組みを構築することが可能となります。
入荷予定データがあれば、いつ、何が、どれだけ入荷するか、事前に把握することができます。
具体的には、入荷量が多い場合には、既存の在庫を移動させて、事前に十分な入荷スペースを確保しやすくなります。また、作業者が不足すると予想できる場合には、事前に作業応援を依頼しやすくなるのです。
一方、入荷量が少ない場合には、入荷担当者は事前に他工程の応援に回すことの計画も立てられます。
作業品質の面でもメリットが多くなります。仮に、ベンダーから精度の高い入荷予定データが入手できれば、その入荷予定データを利用して、入荷作業時に検品を行うことができます。正確な検品作業が行えれば、在庫精度の向上、棚卸作業時の棚卸誤差の低減、欠品の回避、ピッキング時に商品が探せないという無駄の排除等に寄与します。
基本統計量に関する基本的な知識の整理
基本統計量とは
基本統計量とは、データの基本的な数値の特徴を表す値のことです。基本統計量は、平均、中央値(メジアン)、最頻値(モード)、標準偏差、範囲、最小、最大、合計、データの個数等から構成されます。
・平均値:全体の総和をデータ数で除した値。日常的にも利用することが多い。
・中央値(メジアン):データを降順や降順で並べた時に、その真ん中に位置する値。
・最頻値(モード):データの中で、最も頻度が多い値。なお、最頻値は、小数点のデータを取り扱い際や、データ個数が少ない場合などでは、算出されない場合がある。
・標準偏差:平均値からのデータのばらつきを表す。標準偏差の値が小さいと、データの分布のばらつきが少なく、平均に近い分布であることを表す。
・範囲:最大と最小の範囲。
・最小:最も小さい値
・最大:最も大きい値
・データの個数:基本統計量で対象としたデータの行数を意味する。
エクセルの基本統計量の算出方法
基本統計量は、エクセルの標準機能を用いて、とても簡単な操作で利用できます。なお、エクセルのツールバーに基本統計量が見当たらない場合には、アドインで基本統計量が使えるように設定する必要があります。
エクセルで基本統計量を算出する詳しい手順は割愛しますが、対象となるデータの範囲を選択して、数回クリックするだけの簡単操作です。
表2に、日次入荷件数データの基本統計量を示します。表2のエクセルで出力した基本統計量の結果を用いて、データの分布の特徴を把握することができます。
なお、エクセルの基本統計量では、標準誤差、分散、尖度、歪度も算出されますが、本稿では、それらの概念はやや難解なため、割愛しました。
表2 日次入荷件数データの基本統計量
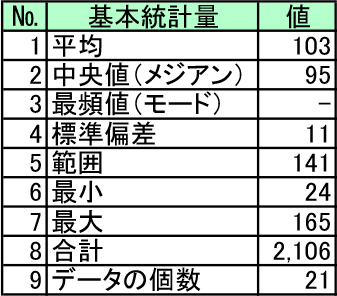
出所:各種資料より日通総研作成
基本統計量をどのように利用するか
基本統計量を用いれば、データ分布の特徴を把握しやすくなります。物流データを入手した際には、生のデータ全体を俯瞰したあとに、基本統計量を算出すれば、かんたんに、データの分布の特徴を把握することができます。
データの分布は、棒グラフ、折れ線グラフなどで、可視化することができます。そのグラフと基本統計量を併用することで、データの分布の特徴を、素早く把握することができます。
おわりに
物流データを取扱う際に、データの分布を俯瞰するための手法として、基本統計量が使われます。
“統計”は、中学校や高校で学ぶ数学に含まれるため、やや難しいと感じる方も少なくないと思われます。
しかし、物流データの取り扱いでは、難解な数式や関数などを使わなくても、基本統計量の取り扱いは可能です。上記のように、エクセル等の表計算ソフトを用いれば、とても簡単に、基本統計量を把握できます。
最後に、本稿が、物流データや基本統計量を取り扱う皆様の一助になりましたら幸いです。
(この記事は2020年5月8日時点の情報をもとに書かれました。)










