






はじめに
物流におけるデータ分析アプローチは、在庫管理、ルート最適化、需要予測などさまざまな側面で求められます。しかし、その実現にはデータから得られる洞察が欠かせません。この記事では、Pythonというプログラミング言語を使った物流データの統計分析に焦点を当て、データ分析が物流業界での意思決定と改善にどのように役に立つかを見ていきます。
具体的には、python上の機能であるPandasやNumPyなどのPythonライブラリを活用したデータ処理、そして統計分析の具体例を、実データを用いたケーススタディを通じて解説します。
Pythonエディタ導入
今回使用するエディタ(プログラミングにおいてソースコードの記述、編集(コーディング)を行うためのソフト)はAnacondaです。Anacondaは、他のエディタと異なりデータ処理や分析、機械学習などに必要なNumPyやPandasなどのライブラリ(※)やツールが一括で提供されています。このため、Pythonを使ったデータ分析や機械学習を始める際に必要な前処理を省くことが可能です。本ブログではAnacondaのダウンロード方法についての説明は割愛を致しますが、先ずはご自身のパソコンにAnacondaをインストールすることがスタートになります。
Anacondaサイト
因みに、Anacondaには「Jupyter Notebook」というインタラクティブな環境が含まれています。これは、コードを書いてその結果をリアルタイムで見ることができる便利なツールです。以降の説明では、Jupyter Notebookの画面にてプログラミング方法を説明していきます。
※ライブラリ:特殊な機能を保有した関数・クラスを示します。
基礎的なプログラミング演習
先ずは、Jupyter Notebook上に、「こんにちは!」と出力させるプログラミングを出力してみましょう。
Print関数の()内に、こんにちは!とエディタ上に入力・実行することで、実行結果(入力欄の下部)に「こんにちは!」と出力されています。ここで示す関数とは、「何らかの値を渡すと、その値に応じた何らかの値を返すもの」と言えます。エクセル機能ならば、Sum関数やXlookup関数などが該当いたします。

続いては、簡単な足し算です。以下の例では、x・yという変数(変数とは、値を代入する箱をイメージ)を作成して、各変数に10・20という整数を代入、最後にx+yという足し算処理を行い、先ほどご紹介したprint関数で合計値を出力しています。

Pythonライブラリ
続いてライブラリのご紹介です。Pythonのライブラリは、Pythonを使ってプログラムを書く際の便利なツールや機能が備っています。例えば、表形式のデータ処理を実行するPandas・NumPyが代表的です。またPandasはデータの読み込み、フィルタリング、集計といった作業を効率的にし、NumPyは数値計算をサポートします。
その他にもグラフを描画する場合には、MatplotlibやSeabornが活用可能です。これらを使うと、データから直感的でわかりやすいグラフを簡単に作成できます。Matplotlibは多様なグラフスタイルを提供し、Seabornはより美しく魅力的なデザインのグラフを作成することが可能です。
Pythonのライブラリは、プログラミングを始めたばかりの人でも手軽に使えるのが魅力です。ライブラリを利用することで、プログラムを効率的に作成、複雑な処理を簡単に行うことが可能です。ライブラリを学ぶことで、自分のプロジェクトや興味のある分野でPythonの力を最大限に引き出すことが可能です。
Jupyter上でライブラリを用いる際には、impot {ライブラリ名}+ as + {モジュール名}を設定してあげる必要があります。import文の後ろに「as」キーワードを使用することで、インポートするライブラリ名に別名を付けることができます。別名を付けることで、以降のプログラムでは、別名で利用することができます。

前提条件
ここから統計基礎分析にあたり、下記データを使用いたします。今回は22年1月~22年12月の物流データ(入荷量・出荷量・デバニング・バンニング)を用いて、作業員の各業務時間にどれくらいの影響を与えているのか、またそこからどのような示唆が得られるのかという観点より分析作業を進めて参ります。
まずは、上記の物流データをpython上に読み込んでいきます。python上にデータを読み込む際には、先程インポートしたpandasのread.csv()を使用いたします。またdisplay関数を使って、読み込んだデータをJupyter上にアウトプットしてみます。
※pandasライブラリの特徴にpandas.DataFrameと呼ばれるオブジェクトがあり、2次元の表形式データ処理が可能です。
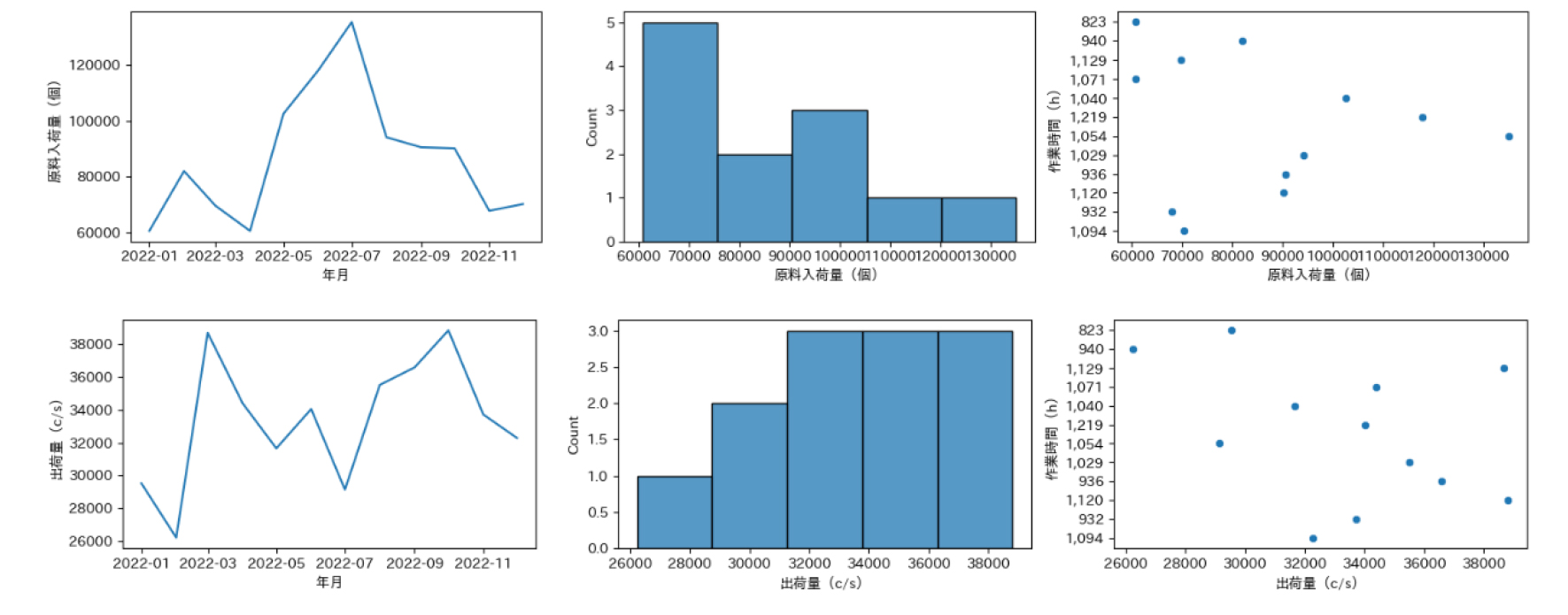
統計基礎分析:各変数の時系列・ヒストグラム・散布図
続いては各変数の時系列・ヒストグラム、作業時間(h)と各変数の散布図を出力してみます。

for文は、ある処理を繰り返し実行するための言語です。具体的には、指定したリストや範囲などの要素を順番に取り出し、それぞれの要素に対して同じ処理を繰り返し実行します。
このコードでは、リスト[“作業時間(h)”, “資材入荷量(個)”, “原料入荷量(個)”, “出荷量(c/s)”, “デバニング”, “バンニング”]内の各要素を変数cに代入し、その要素ごとに以下の処理を繰り返しています。それ以外の構文の処理は下記の通りです。
・plt.figure(figsize=(15, 3))で、図のサイズを指定して新しい図を作成します。
・plt.subplot(1, 3, 1)で、1行3列のサブプロットのうち、1番目の位置に現在のサブプロットを設定します。
・sns.lineplot(y=c, x=”年月”, data=df)で、指定した変数と”年月”列を使用して折れ線グラフを作成します。
・同様に、2番目と3番目のサブプロットに対してもヒストグラムと散布図を作成します。
・plt.tight_layout()で、サブプロット間のスペースを調整します。
・plt.show()で、作成した図を表示します。
今回のブログはここまでです。次回ブログでは、変数間の相関関係・重回帰分析等について、実際のケーススタディを通じて学んでいきたいと思います。お楽しみに!
(この記事は、2023年12月30日時点の状況をもとに書かれました。)






